10个基本的数据建模面试问题 *
最好的数据建模专家可以回答的全面来源的基本问题. 在我们社区的推动下,我们鼓励专家提交问题并提供反馈.
现在就聘请顶级数据建模专家Interview Questions
The Conceptual Model
该模型用于描述业务数据策略设计初始阶段的概念结构. 它定义了实体名称和实体关系,但不关注技术问题, computer systems, 或者数据库管理系统.
The Logical Model
该模型用于数据库管理系统的实现,它关注的是数据的逻辑结构. 它是一种分期模型,既可以面向用户,也可以面向系统. 除了实体名称和实体关系之外, 模型定义属性, primary keys, 和每个实体中的外键.
物理数据模型
这是数据模型的最后阶段,它不仅与特定的数据库管理系统相关, 同时也说明了操作系统, storage strategy, data security, and hardware. 该模型描述了模式细节, columns, data types, constraints, triggers, indexes, replicas, and backup strategy. 该模型承载了DBA和数据库开发人员实现数据库的实际设计蓝图.
Normalization 是否在保持数据完整性的同时减少数据冗余. 这是通过主键和外键在表之间创建关系来实现的. 归一化过程包括1NF(第一范式)、2NF、3NF等.
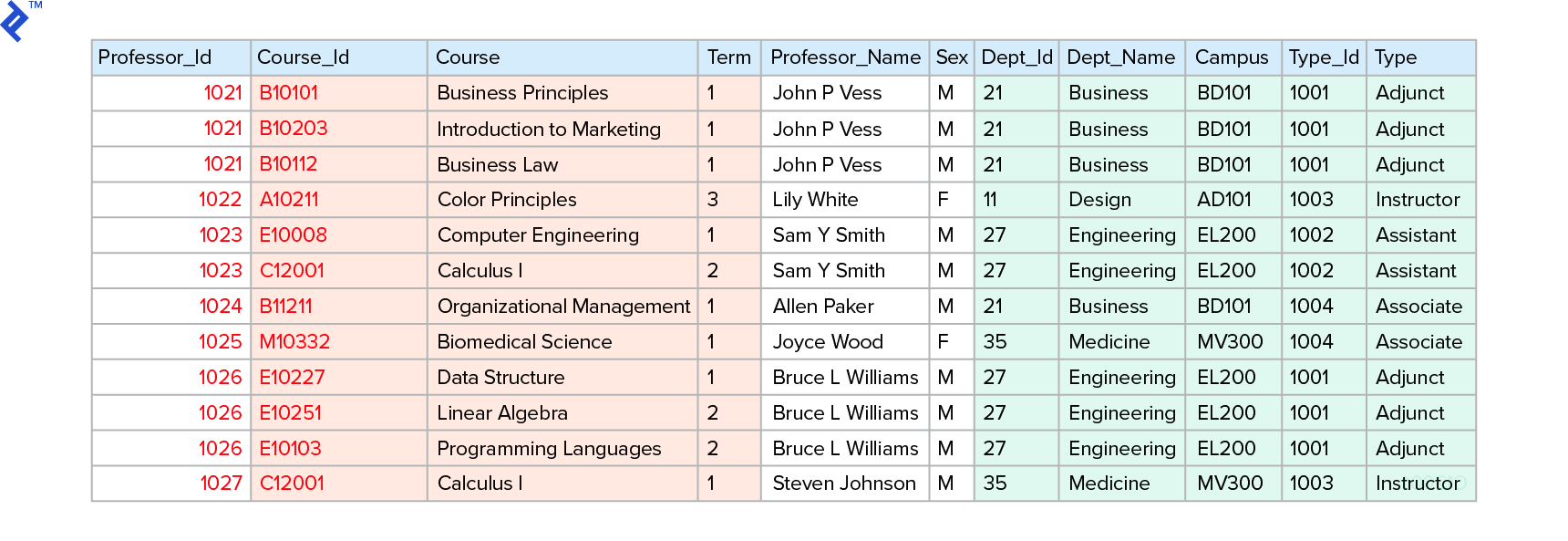
1NF:消除实体中重复的属性组,并为每个实体实现一个主键. (By definition, 每个单元格由其唯一主键和列标识符的组合来标识.)
For example, 在这种大学课堂模式中, 每个记录条目由主键唯一标识 [Professor_Id] + [Course_Id].
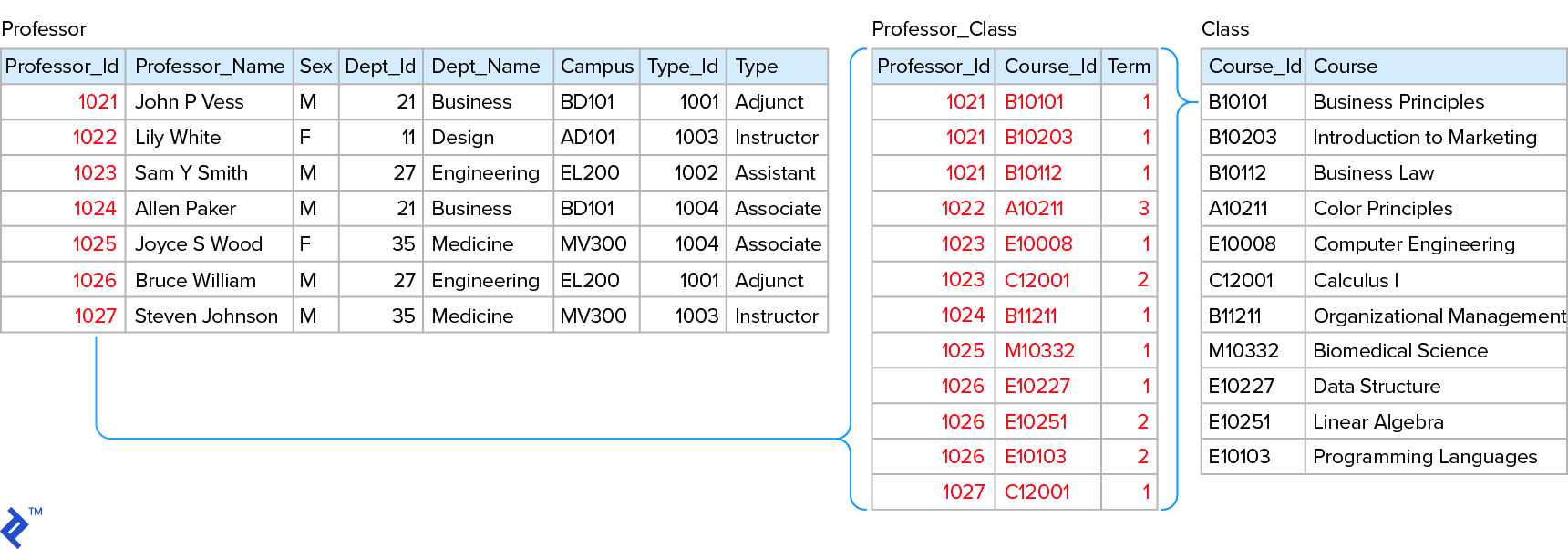
2NF:这包括1NF,但所有的非键属性(如.e.(即主键列以外的列)必须依赖于主键. 如果没有,将这些属性分离到另一个实体中. 在这个阶段,您正在解决关系应该是一对多还是多对多的问题. (See example below.)
为了将1NF的例子扩展到2NF,我们包括了“动词关系”,但不包括“形容词关系”.“Course”栏部分取决于主键 [Professor_Id] + [Course_Id] +[词]. Therefore, 我们创建实体“Class”和“Professor-Class”来建模多对多关系.
3NF这包括2nf +, 所有字段(列)都不能与表中的主键具有传递函数依赖关系(列之间的间接关系). 在上面的1NF示例中,如果我们知道 [Course+Term] we learn the [Professor_Name]. When we learn the [Professor_Name] we have the [Dept_Name]. Therefore [Course+Term] 传递函数依赖于 Department.
At this stage, 我们正在使用外键创建引用表——类似于我们在2NF中所做的, 但对于“形容词关系”也一样.
继续我们的例子, [Type], [Dept_Id], [Dept_Name] and [Campus] 有传递函数依赖. 它们不依赖于主键 [Professor_Id],所以我们创建了两个参考表:
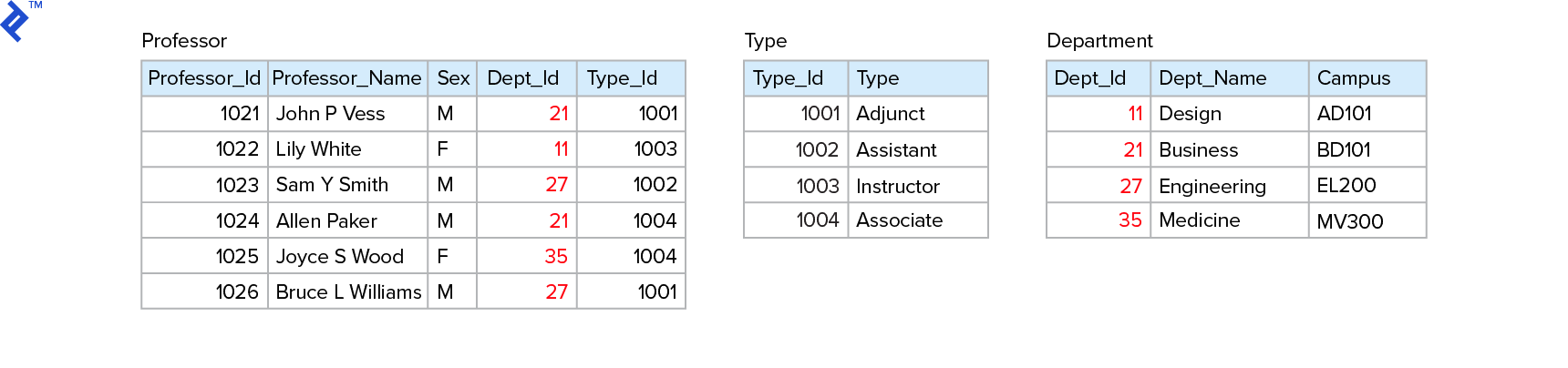
在大多数情况下,3NF阶段足以实现规范化.
Denormalization, on the other hand, 是否在规范化数据库上使用了优化过程来提高数据分析的查询性能. 这是一个从3NF(或更高形式)恢复到1NF的过程. 非规范化模型有时也称为维度模型. 它通过消除复杂连接减少了所选查询的运行时间, 它将详细数据预聚合为摘要级数据, 它把数据存储在a中 separate 使用内存和列存储技术的非规范化1NF (c).f. 本页的相关问题.)也就是说,原始的3NF模型仍然是原始的数据源.
您可以在任何数据仓库维度模型设计策略中找到该策略的变体.
In-memory analytics 是在RAM中缓存整个数据库的方法. 在过去,RAM非常昂贵,因此这种方法的成本往往令人望而却步. 当时的解决方案是使用数据索引并存储预聚合的数据.
这个过程中最慢的部分是从磁盘中检索数据, 因为有限的系统内存无法容纳整个数据库. Today, RAM的价格更实惠, 因此,当涉及到内存分析时,业界现在的采用率要高得多.
A column store 在数据库中存储和检索数据的现代方式是什么. 过去,数据是面向行并水平存储的. 为了检索数据,它被水平读取,就像从左到右阅读一本书一样. 因此,在使用硬盘之前,必须将整个数据集从硬盘驱动器读取到RAM中.
现在,列式存储(或 columnar store)数据库使用面向列的存储,垂直存储数据. 因此,在检索数据时,硬盘驱动器读取次数最少——数据库只读取查询实际包含的列.
For example, 假设您有一个“客户销售”数据集,其中包含所有客户的个人和销售信息的20列, with a million rows. You only need the [Customer Name], [Address], and [Purchase Date] columns. Using a column store, 数据将只从硬盘读取量最少的三列中读取, 大大减少读取时间.
Also, 列存储提高了压缩的可能性, 因为单个字段内的数据值彼此高度相似——这是压缩算法所依赖的.
申请加入Toptal的发展网络
并享受可靠、稳定、远程 自由数据建模专家的工作

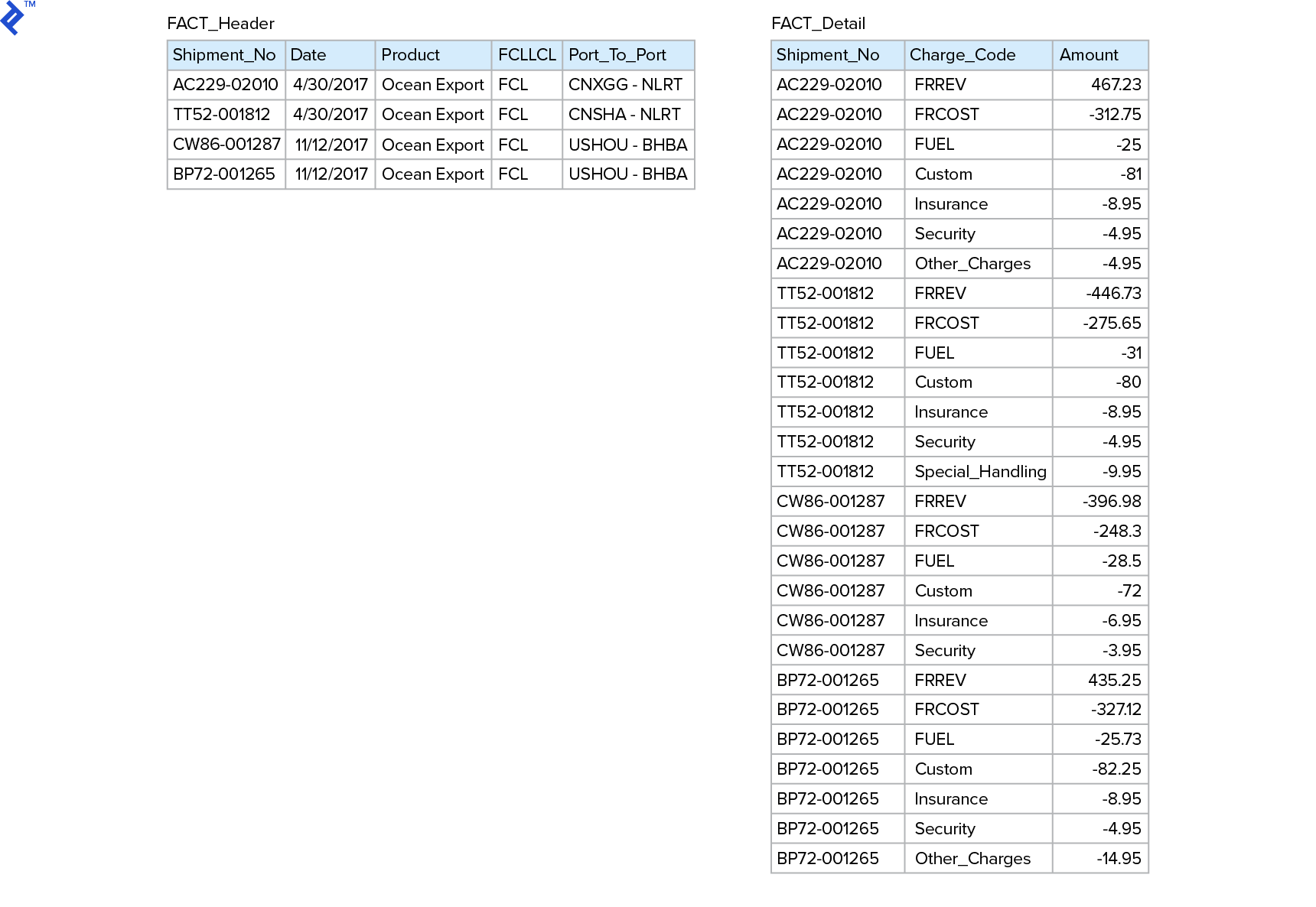
而不是水平扩展收费行项目, 模型应该分成一个FACT_Header表和一个Fact_Detail表. 记账行项目的列名应该被转移到一个“Charge_Code”列中,作为内存/列存储最佳实践的一个维度.
Document Databases
文档数据库主要用于像JSON这样的自描述文档格式的半结构化数据存储. 数据文档结构(由键-值层次结构定义)可以相同,也可以不同. 具有相同属性的文档将被分组到“集合”中,这类似于关系数据库中的表.
{
"id": "IC001",
“类别”:“冰淇淋”;
“产品名称”:“庆典饼干蛋糕”,
"Size": 2.5,
"Details": {
"shape": [
{"id": "001", "type": "Round"},
{"id": "002", "type": "Sheet"},
{"id": "003", "type": "Roll"},
{"id": "004", "type": "Dome"}
],
"cream flavor": [
{"id": "1001", "type": "Mint"},
{"id": "1002", "type": "Oreo"},
{"id": "1045", "type": "Chocolate"},
{"id": "1021", "type": "芝士蛋糕"},
{"id": "1022", "type": "Vanilla"},
{"id": "1033", "type": "Cookie"},
{"id": "1014", "type": "Butter Pecan"}
]
},
“图像”:“X562FCDQX73DS; L9EBWIDKFDKNLUWNJSNA: IU * DWJHIJDSJDKALijnkw8!WEJD#KLJSATEGD..."
}
Column Databases
在列数据库中,数据是面向列而不是面向行存储的. 这种类型的数据库在分析数据库查询期间针对I/O进行了优化. NoSQL列数据库的一些例子包括Google的Big Table、Apache Cassandra和HBase.
Key-value Databases
和文档数据库一样, 键值数据结构类似于字典或映射, 但是在这种情况下,它不能嵌套. 它使用一个惟一的键(可以是合成的,也可以是哈希算法生成的)来指向它自己的值列表. 该值可以是不同的类型:string、JSON、basic large object (BLOB)等.
{
name: "Jimmy Johnson",
email: "jjohnson@test.com",
街道:“13278 Southside Blvd”;
city: "Orlando",
state: "FL",
country: "USA"
}
Cache Systems
类似于键值对, 频繁访问的数据存储在内存中,以便快速检索和访问. Redis和集群Memcached就是这样的例子. (而Memcached可以被rdbms使用, 它只能在一台服务器上提供内存, 而NoSQL提供集群中所有服务器的内存场.)
Graph Databases
In a graph database, 对象表示为节点,对象之间的关系表示为边. 边和节点都有定义的属性/属性,这些属性/属性可以存储为键值对. 例如Neo4J、InfiniteGraph、OrientDB、Virtuoso和Allegro.
注:更多信息请参见 NoSQL数据库权威指南 在Toptal Engineering博客上.
Flexibility
关系数据库只允许结构化数据, 而NoSQL数据库提供了存储结构化数据的灵活性, semi-structured, or unstructured data.
Dynamic Schema
在关系数据模型中,需要预先定义模式. 在现实世界中,应用程序不断发展,需要进行更改. 这个过程非常昂贵和耗时. In recent decades, 与简单的文本和数字相比,数据对象更加复杂. For example, 使用某些rdbms很难有效地查询地理空间数据(由GPS坐标组成的多边形).
动态模式提供了一种轻松添加复杂数据对象的解决方案,因为您可以在应用程序增长时修改或添加新元素,而无需预定义的模式.
Large Blobs/Rich Media
现在在很多情况下, 我们需要一种更灵活的方式来存储像语音文件这样的数据类型, video files, images, etc. 曾经被认为是最佳实践的地方是简单地为这样的数据存储到文件系统的链接, 使用NoSQL可以直接存储它们.
除了避免脆弱的链接之外,这样做的好处是数据库可以将对象分解成小块,并将它们分布到服务器池中,从而获得最终的性能增益.
Sharding
分片是将数据划分并分发到更小的数据库中的过程,以便更快地访问数据. 数据在应用程序不知情的情况下分布在许多服务器上. 数据和查询负载均匀地分布在服务器上. 这样,如果其中一个出现故障,可以毫不费力地替换它,而不会中断应用程序.
与单服务器设置相比, 这个过程将大数据任务分解成小块,以便它们可以在分布式服务器群中同时处理.
Replication
NoSQL数据库在自我解析和自我平衡方面是相当复杂的. 它们提供故障转移和恢复选项. 他们通过将数据库分布在许多地理/区域数据中心来实现这一点. 如果一个区域出现问题,它会自动依赖于其他区域. 这种体系结构允许不间断(“高”)可用性, 因为数据是跨不同数据中心复制的.
Scaling
从一组分布式服务器节点开始(所有服务器节点都是对等节点,没有共享资源,可以独立工作), 随着数据库大小的增加, 可以跨数据中心动态添加其他服务器节点,而不会中断或受到限制.
在当前的RDBMS体系结构中, 通常只能通过在适用的硬件限制内添加内存和硬盘驱动器来进行扩展, although 原生分片支持正在进行中 in some cases.
One-to-many
NoSQL中的一对多关系在文档数据库中建模,1:M关系表示为嵌入在另一个文档数据类型中的父子关系实体对象. For example:
{
"order_id": "12345",
:“order_date 1/21/2019”,
“customer_id”:“123456”,
"order_details": [
{
"item_id": "2345",
"qty": 2,
"unit_price": 157.75,
"sales_price": 315.5
},
{
"item_id": "2110",
"qty": 1,
"unit_price": 75.25,
"sales_price": 75.25
},
{
"item_id": "1760",
"qty": 3,
"unit_price": 55,
"sales_price": 165
}
]
}
这里,下面的每个物体 order_details 子文档是否具有不同的文档数据类型.
Many-to-many
多对多关系使用两个文档集合建模,其中嵌入实体对象引用来自带有标识符/键的第三个集合的相关文档. 在检索数据时,在应用程序级别实现/维护M:N关系. 下面的示例使用该标识符 class_id 解决教授和学生收藏之间的M:N关系.
教授的收藏是这样的:
{
“Professor_id”:“1021”,
"Name": "John P Vess",
"Type": "Adjunct",
"class_details": [
{
"class_id": [
"B10101",
"B10203",
"B10112"
]
}
]
},
...
学生的收藏是这样的:
{
“Student_id”:“201727542”,
"Name": "Mary Carson",
“类型”:“本科生”,
"class_details": [
{
"class_id": [
"B10101",
"B10107",
"B10119"
]
}
]
},
{
“Student_id”:“201821230”,
"Name": "Jerry Smith",
“类型”:“本科生”,
"class_details": [
{
"class_id": [
"B10101",
"B10203",
"M10332",
"C12001"
]
}
]
},
...
最后,由其他两个集合引用的类集合看起来是这样的:
{
"Class_id": "B10101",
“课程”:“商业原则”
},
{
"Class_id": "B10203",
“课程”:“市场营销概论”
},
...
关系有三种程度,称为:
One-to-one (1:1)
在这里,一个实体中的一个事件可以关联到另一个实体中的一个事件或零事件.
例如:具有“tag number”属性的“tag”表可能与具有唯一车辆识别号(VIN)为主键的“vehicle”表具有1:1的关系. 也就是说,给定的车辆可能有也可能没有标签,但不能有多个标签.
继续这个例子, 库存中可能有机动车标签, 但他们还没有分配车辆.
One-to-many (1:M)
In this case, 一个实体中的一个事件与另一个实体中的许多事件相关(或可以相关).
教授可以教很多课. 因此,在“教授”表中,每个教授记录可以与许多类记录相关联.

相反的关系是多对一(M:1)——这只是一个语义问题, 这取决于你首先提到的是哪张表.g.,“class”表与“professor”表的关系为M:1.
Many-to-many (M:N)
在这种关系中, 一个实体中的许多事件可能与另一个实体中的许多事件相关.
E.g.在美国,一个学生可以上很多课,一个课可以包含很多学生. 要实现这种关系,需要一个中间表将学生与课程链接起来. 我们可以称这个表为“学生-课程”表.
因此,总共需要三个表:“student”、“class”和“student-class”.从“学生”到“学生-班级”的距离是1:M. 从“student-class”到“class”是M:1. 最后,使用中间表,“学生”到“班级”是M:N.

在星型模式中,有一个或多个事实表引用星型模式中的任意数量的维度表. Usually, 星型模式中的事实表是使用外键和聚合(有时称为“度量”)从第三种范式(3NF)创建的.”)
在开发数据仓库和维度数据集市时使用它.
下面的星型模式显示了两个事实表, “fact_教授”和“fact_教授class_detail”,和维度表包括“Dim_Type”,” “Dim_Department,” “Dim_Date,” and “Dim_Class”. Foreign keys are [Type_Id], [Dept_Id], and [Date_Key]. Measures (not pictured; these are calculated sums, minimums, maximums, averages, counts, 和不同计数)将包括的总和 [Credits], the distinct count of [Professor], the distinct count of [Class_Id], and [Hired_Days] 哪个可以计算出两者之间的差异 [Hired_Date] and today().
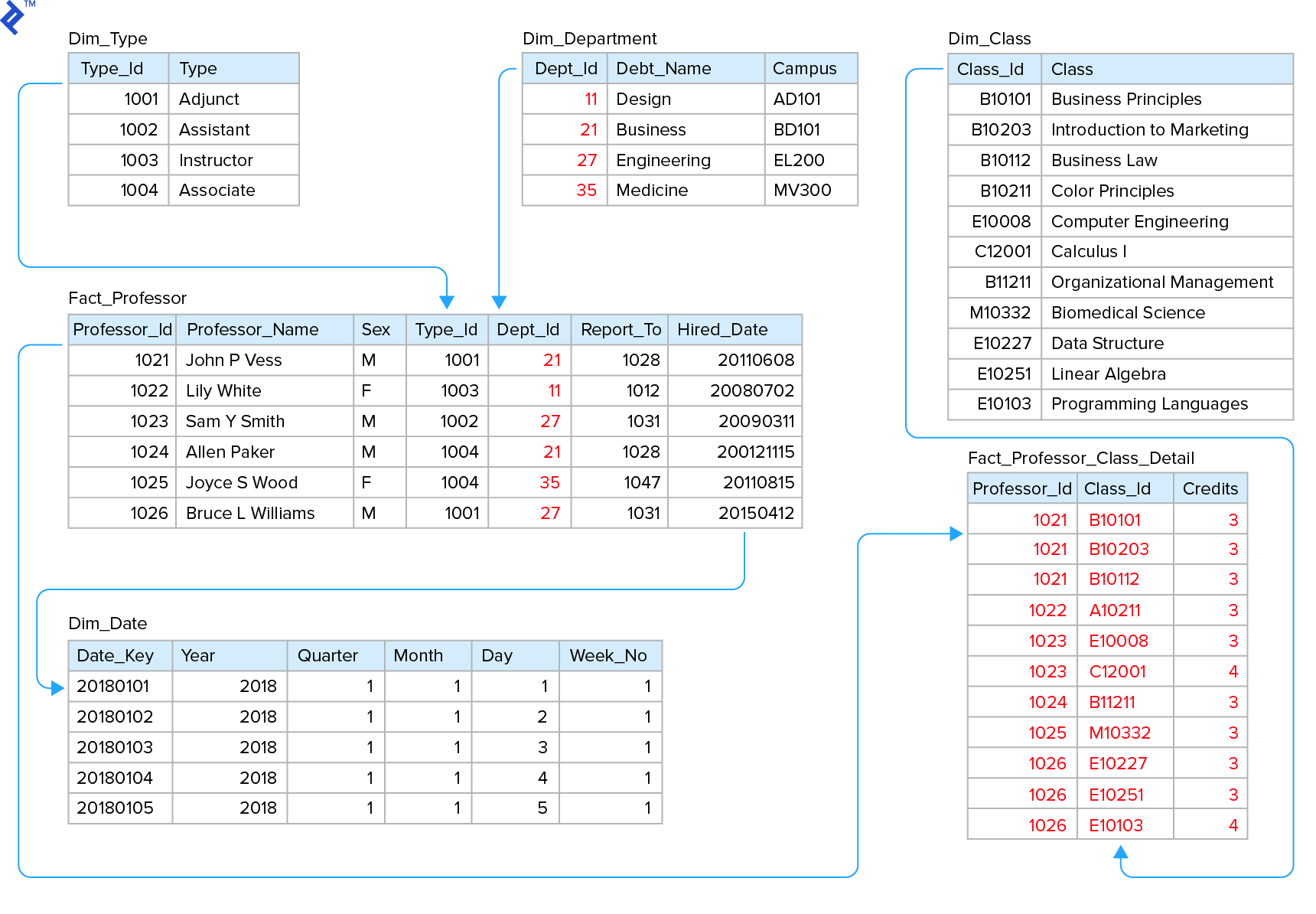
从小型NoSQL数据库开始,可以使用动态模式构建该模型. That is, 它将允许实时更改和调整模式, 而不是在应用程序开发期间使用预定义的模式. However, 保证数据的一致性,解决数据实体之间的关系, 最初使用实体关系(ER)模型来定义实体, relations, attributes, 主键和外键. ER模型——因为它是通过定义规范化的——将确保数据的完整性. 然后可以将模型转换/非规范化为嵌入父子关系的实体模型. For example:
从一个3NF模型开始,在实体“Order”中以“order_id”为主键,在实体“Detail”中使用外键:
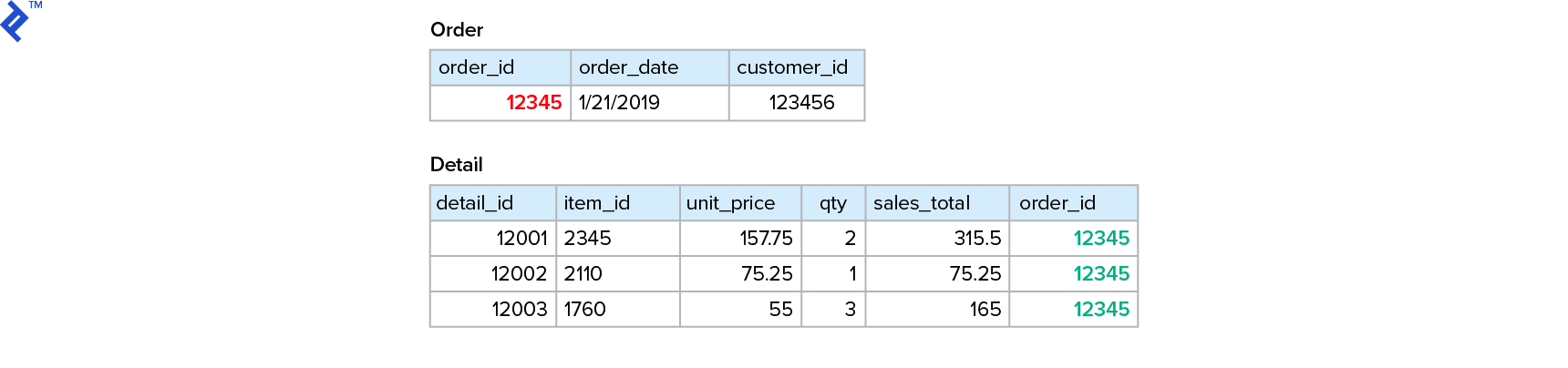
反规格化后,上述3NF模型如下:

Finally, 你可以将非规范化的表单转换为嵌入父子关系的NoSQL实体模型:
{
"order_id": "12345",
:“order_date 1/21/2019”,
“customer_id”:“123456”,
"order_details": [
{
"item_id": "2345",
"qty": 2,
"unit_price": 157.75,
"sales_price": 315.5
},
{
"item_id": "2110",
"qty": 1,
"unit_price": 75.25,
"sales_price": 75.25
},
{
"item_id": "1760",
"qty": 3,
"unit_price": 55,
"sales_price": 165
}
]
}
面试不仅仅是棘手的技术问题, 所以这些只是作为一个指南. 并不是每一个值得雇佣的“A”候选人都能回答所有的问题, 回答所有问题也不能保证成为A级考生. At the end of the day, 招聘仍然是一门艺术,一门科学,需要大量的工作.
Why Toptal
提出面试问题
提交的问题和答案将被审查和编辑, 并可能会或可能不会选择张贴, 由Toptal全权决定, LLC.
寻找数据建模专家?
Looking for Data Modeling Experts? 查看Toptal的数据建模专家.

Lian Yagoda
Lian在不同的BI平台上有十年的经验, 作为BI开发人员和技术支持顾问. 她是数据建模专家, querying, manipulation, 以及数据输出的可视化, 她喜欢用推理, Tableau, Qlik Sense, Power BI, and Looker. Lian每天都喜欢用她的技能为令人兴奋的技术进步做出贡献.
Show More
Oliver Holloway
奥利弗是一位多才多艺的数据科学家和软件工程师,拥有十多年的经验和牛津大学的研究生数学学位. 从为初创公司构建机器学习解决方案,到领导项目团队,再到在高盛(Goldman Sachs)处理大量数据,我的职业任务都有. With this background, 他擅长快速掌握新技能,为最苛刻的企业提供强大的解决方案.
Show More
Christopher Karvetski
Dr. Karvetski作为一名数据和决策科学家有十年的经验. 他曾在学术界和工业界的各种团队和客户环境中工作, 并被公认为优秀的沟通者. 他喜欢与团队合作,构思和部署新颖的数据科学解决方案. 他精通R、SQL、MATLAB、SAS和其他数据科学平台.
Show MoreToptal Connects the Top 3% 世界各地的自由职业人才.
加入Toptal社区.